July 05, 2025
Blog PostWhat is a Large Language Model (LLM)?

How does a Large Language Model (LLM) work?
A Large Language Model (LLM) is an advanced artificial intelligence (AI) algorithm capable of understanding, generating, summarizing, and predicting text. Built on deep learning and transformer models—neural networks designed for handling sequential data—LLMs operate by analyzing vast datasets, sometimes derived from the internet, to grasp the nuances of human language. This process involves deep learning techniques that examine the probabilistic relationships between characters, words, and sentences, allowing the model to generate coherent and contextually relevant text without manual guidance.
Initially trained on broad data, LLMs undergo further refinement through techniques like fine-tuning or prompt-tuning, enabling them to excel in specific tasks such as question answering, content generation, or language translation. The concept of LLMs isn’t new; it began with earlier AI endeavors, such as the Eliza model from 1966, expanding dramatically in capabilities with modern computational and algorithmic advancements.
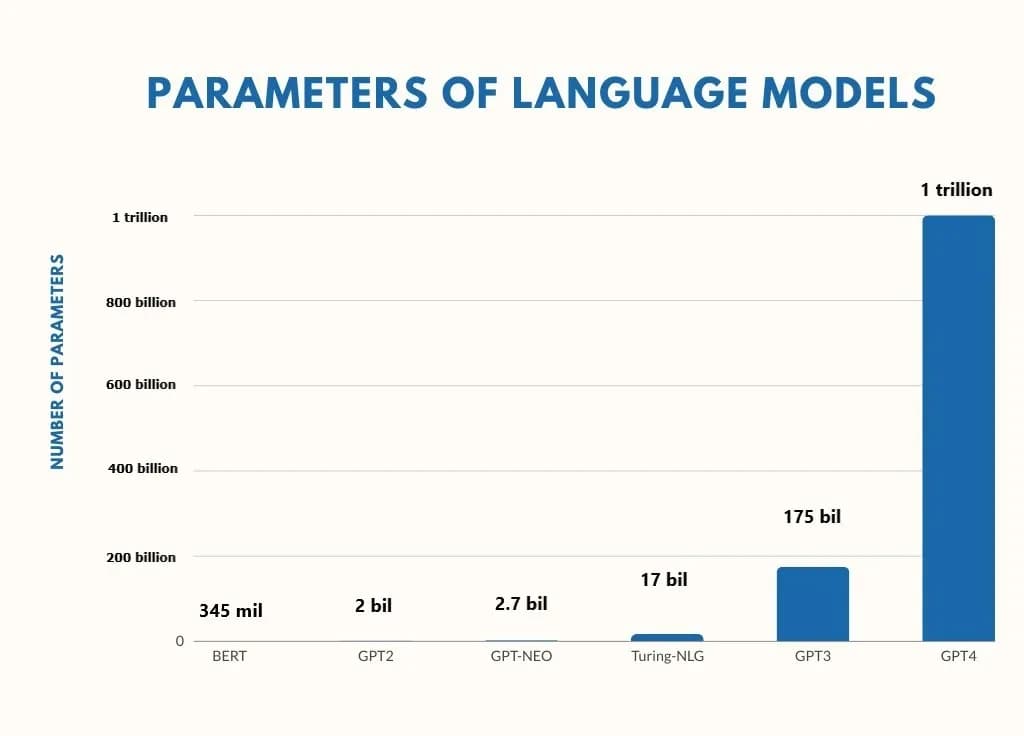
LLM Parameter Growth Over the Years
In 2018, Google introduced BERT (Bidirectional Encoder Representations from Transformers), a groundbreaking development in the field of natural language processing (NLP) with 345 million parameters. BERT's innovative approach to understanding the context of words in search queries significantly enhanced the accuracy of search results and language understanding tasks. Following BERT's success, the AI research community saw a rapid evolution in language model complexity and capability. GPT-2, unveiled by OpenAI, expanded the landscape with its improved capacity for generating coherent and diverse text. Subsequent developments included GPT-Neo, an open-source alternative aiming for accessibility and transparency, and Turing-NLG by Microsoft, which pushed the boundaries further in terms of model size and language comprehension. The launch of GPT-3 marked a significant milestone, offering unprecedented text generation and task flexibility, setting the stage for GPT-4. With a staggering one trillion parameters, GPT-4 represents the pinnacle of this evolutionary path so far, offering deeper understanding, more nuanced text generation, and broader applicability across various domains, showcasing the rapid advancement and scaling in the field of AI and language models.
Regarded as a subset of generative AI, LLMs are pivotal in creating text-based content, leveraging their substantial training data and deep learning to infer and create new information. The sophistication of LLMs, often measured in billions of parameters, marks a significant leap in AI's ability to mimic and extend human language and communication. These models, sometimes referred to as foundation models since 2021, provide a versatile base for a multitude of AI applications across various domains, pushing the boundaries of what AI can achieve in understanding and generating human language.
How Do LLMs Work?
Neural networks
To facilitate deep learning, Large Language Models (LLMs) utilize the structure of neural networks. Similar to how the human brain consists of neurons that interlink and transmit signals among themselves, an artificial neural network is made up of interconnected nodes. These networks are structured into multiple layers: there's an input layer where data enters, an output layer where the final processing results are delivered, and between them, several hidden layers. Information only moves from one layer to the next when the output from a layer meets a predefined threshold, ensuring that the neural network selectively processes and passes on information.
Machine learning and deep learning
At their core,LLMs are grounded in the principles of machine learning, a branch of artificial intelligence focused on enabling programs to learn from vast datasets without explicit human instruction. These models leverage a specialized form of machine learning known as deep learning. Deep learning allows models to autonomously identify patterns and distinctions in data, although they often benefit from some level of human refinement.
The essence of deep learning lies in its use of probabilistic methods to "learn." For example, considering the sentence "The quick brown fox jumped over the lazy dog," a deep learning model might note the frequency of letters like "e" and "o," which appear four times each, deducing their commonality in English text.
However, learning from a single sentence is beyond the capability of a deep learning model. Instead, by examining trillions of sentences, it gradually acquires the ability to predict the most logical continuation of a given sentence fragment or to craft sentences on its own. This immense learning process enables LLMs to understand and generate language with a high degree of nuance and coherence.
Transformer models
The type of neural networks that power Large Language Models are known as transformer models. These models are adept at grasping the context, a critical aspect of human language, which is inherently reliant on the context for meaning. Transformer models employ a method called self-attention, which enables them to identify the intricate relationships between elements within a sequence. This capability surpasses other machine learning approaches in understanding context, allowing them to discern how the end of a sentence relates to its beginning and the interconnections between sentences within a paragraph.
Such a feature empowers LLMs to decode human language, even when the language is ambiguous, structured in previously unseen arrangements, or placed in novel contexts. To some extent, they "comprehend" semantics, as they can link words and concepts based on meanings inferred from witnessing these associations millions or billions of times.
Applications of Large Language Models (LLMs)
Large Language Models are versatile tools capable of undertaking various tasks. A prominent application is their role in generative AI. When prompted or asked a question, they excel at generating textual content. For example, the widely known LLM, ChatGPT, is adept at creating essays, poems, and more in response to user prompts.
Training LLMs involves utilizing vast and intricate data sets, which can encompass programming languages. This makes some LLMs invaluable for developers, aiding in coding tasks such as writing functions or completing a program based on an initial code snippet. Beyond programming, LLMs find utility in diverse areas, including:
- Analyzing emotions in text
- Enhancing customer service experiences
- Powering chatbots
- Improving online search capabilities
- Content generation
- SEO
- Summarization and grammar
- Image generation
Noteworthy examples of LLMs in the real world encompass ChatGPT by OpenAI, Google's Bard, Meta's Llama, X’s Grok, and Microsoft's Bing Chat. GitHub's Copilot stands out as a specialized tool for coding, demonstrating the flexibility of LLMs beyond processing natural human language.
Strengths and Weaknesses of LLMs
LLMs stand out for their ability to handle unpredictable queries with a flexibility unseen in traditional computer programs. Unlike conventional software that operates within a rigid framework of predefined inputs and commands, LLMs can comprehend and respond to natural language questions in a contextually relevant manner. This capability enables them to perform tasks such as generating detailed answers to complex questions, like identifying the greatest funk bands in history, complete with justifications.
However, the accuracy and reliability of LLMs depend heavily on the quality of the data they are trained on. Misinformation or biased data can lead to incorrect or misleading responses. Moreover, LLMs can sometimes generate "hallucinated" content, fabricating information when unable to provide factual answers. This was notably illustrated when an LLM generated a plausible but factually incorrect news article about Tesla's financial performance.
LLMs may also pose a significant challenge for security. Like any software, applications built on LLMs are vulnerable to bugs and can be manipulated through malicious inputs to elicit harmful or unethical responses. A particularly concerning issue is the potential for confidential information to be inadvertently exposed. When users input sensitive data to enhance productivity, there's a risk that this information could be leaked in future responses to other users, as LLMs incorporate received inputs into their ongoing learning process. This highlights the necessity for users to exercise caution and for developers to continually work on enhancing the security and reliability of LLMs.

Another problem with large language models is their occasional failure to generate accurate images that match the given prompts. The images shown above, created using OpenAI's Dalle-3, demonstrate some of the limitations of AI technology. The original prompt was to create an image of a smiling robot holding a flag that reads "WikiTeq." However, there are noticeable discrepancies in the images: both have spelling errors, and in the image on the left, the robot isn't even holding the flag.
Training LLMs using MediaWiki
MediaWiki serves as an exemplary training environment for LLMs with its mix of structured and unstructured data. It offers a wide range of content, from detailed articles to metadata, enabling LLMs to master both the factual and nuanced aspects of language. Structured elements like infoboxes help LLMs recognize data patterns and facts, while narrative texts deepen their understanding of language's subtleties. Training on MediaWiki not only broadens LLMs' knowledge base but also enhances their ability to interpret and generate contextually rich, accurate content, making it a crucial resource for evolving AI capabilities.

Example of a MediaWiki Infobox
Integrating Artificial Intelligence and Large Language Models into MediaWiki platforms can significantly enhance the user experience and efficiency of content creation and management. By leveraging AI and LLM capabilities, MediaWiki can offer automated content suggestions, improve the accuracy of search results, and even assist in generating and summarizing articles based on vast databases of information. This integration facilitates a more intuitive and interactive environment for users, enabling them to find and contribute knowledge more effectively.
Furthermore, the ability of LLMs to understand and process natural language can dramatically improve the accessibility of information, making it easier for users to query and navigate content. For administrators and contributors, AI-driven tools can aid in monitoring and maintaining the quality of entries, detecting vandalism, and suggesting content improvements. Overall, the inclusion of AI and LLMs into MediaWiki can transform it into a more dynamic, responsive, and user-friendly knowledge repository, aligning with the evolving expectations of digital information consumers.
We have a separate blog, Integrating an LLM into Mediawiki, discussing various ways to integrate artificial intelligence into MediaWiki.
Conclusion
The journey of Large Language Models from their inception to the present day represents a monumental stride in the field of artificial intelligence. These models have evolved from basic text recognition systems to sophisticated algorithms capable of generating human-like text, understanding context, and even coding. The transformative potential of LLMs extends across various sectors, including content creation, customer service, and programming, among others. Despite their remarkable capabilities, challenges such as data reliability, security vulnerabilities, and ethical concerns remain.
However, continuous technological advancements and the integration of LLMs into platforms like MediaWiki highlight the desire to overcome these hurdles. As we move forward, the fusion of AI and LLMs promises to redefine our interaction with digital content, making information more accessible, enhancing creativity, and further blurring the lines between human and machine-generated content. This evolution underscores the importance of responsible AI development and the exciting possibilities that LLMs bring to the digital age, paving the way for a future where technology and human intellect operate in seamless harmony.